ai-gateway-governance-reference-architecture
The AI Gateway: Governance as Enterprise Infrastructure
A field perspective on why AI governance must be architectural — and what forward-thinking enterprises are already building to enforce it
After more than a decade leading enterprise API platforms, I have watched the same mistake play out across organizations of every size and maturity level: governance gets treated as a later-stage concern, deferred until the pain of operating without it becomes undeniable.
In API ecosystems, this was survivable. Teams shipped, scaled, accumulated technical debt — and eventually paid it down. Fragmented design patterns, inconsistent policy enforcement, bloated operations, limited discoverability. Painful, but recoverable.
AI systems will not offer that same runway. And the enterprises that fail to internalize this distinction are about to repeat their most expensive mistake in a system far less forgiving than anything they have operated before.
## The Governance Debt That API Programs Normalized
In traditional API maturity models, governance was almost always a late arrival. Organizations would build APIs rapidly, scale them broadly, and only introduce formal governance structures when the chaos became operationally unsustainable — typically somewhere between maturity Level 3 and Level 4.
The outcomes were predictable: fragmented design patterns across teams, inconsistent policy enforcement, limited API discoverability, and operational drag that compounded over time. These were real costs. But they were recoverable costs. You could retrofit cataloguing, ownership models, deprecation policies, and lifecycle management after the fact. Painful, but the system tolerated the delay.
This pattern became normalized. Governance-last became the de facto approach — not by design, but because it appeared to work. Teams shipped. Organizations scaled. The debt was real but manageable.
That tolerance no longer exists in AI systems. And understanding precisely why is the first step toward building differently.
## Why AI Systems Cannot Absorb Deferred Governance
With LLM-based systems, the governance decisions you do not make at the beginning are baked into the architecture by the time you deliver your first production deployment. Data lineage assumptions. Prompt ownership structures. Model versioning. Access boundaries. Audit trails. Compliance posture.
These are not things you retrofit into an AI architecture. They are things you either designed for from the start — or you did not.
The compounding effects arrive faster in AI than they ever did in API programs. Once usage scales, patterns fragment, shadow AI proliferates across business units, and risk exposure expands in ways that are exponentially harder to address with every passing quarter. The window to build this correctly is before adoption scales — not after.
There is a second dimension that makes this even more acute: the regulatory and compliance environment surrounding AI is moving faster than any technology governance framework in recent memory. Organizations that defer AI governance are not just accumulating technical debt. They are accumulating compliance exposure in a landscape where the rules are being written in real time.
## The RAG Problem Nobody Is Talking About
Many organizations have turned to Retrieval-Augmented Generation as the solution to their AI quality and knowledge problems. RAG is genuinely powerful — it connects LLMs to organizational knowledge in ways that dramatically improve relevance and accuracy.
But RAG has a governance dependency that most implementations ignore entirely.
RAG connects your LLMs to your organizational knowledge. The problem is that organizational knowledge carries all your ungoverned API-era debt with it — unstructured, uncatalogued, undiscoverable data assets that your retrieval pipeline will now surface at AI speed and AI scale.
RAG retrieves what exists. If what exists is a mess — inconsistently structured, poorly tagged, ungoverned — RAG operationalizes that mess faster, at greater scale, and with higher visibility than any previous system. Embeddings and vector databases cannot compensate for structural inconsistency or policy gaps. They inherit them and amplify them.
This means that a clean data catalog is not a follow-up project to RAG implementation. It is a prerequisite. Organizations that treat it as the former will find that their RAG pipelines surface exactly the kind of inconsistent, ungoverned content that erodes trust in AI systems faster than almost anything else.
## An Emerging Control Plane: The AI Gateway
The most architecturally significant pattern I have observed emerging in forward-thinking enterprise environments reframes the entire AI interaction model — and it maps precisely onto lessons that mature API ecosystems took years to learn.
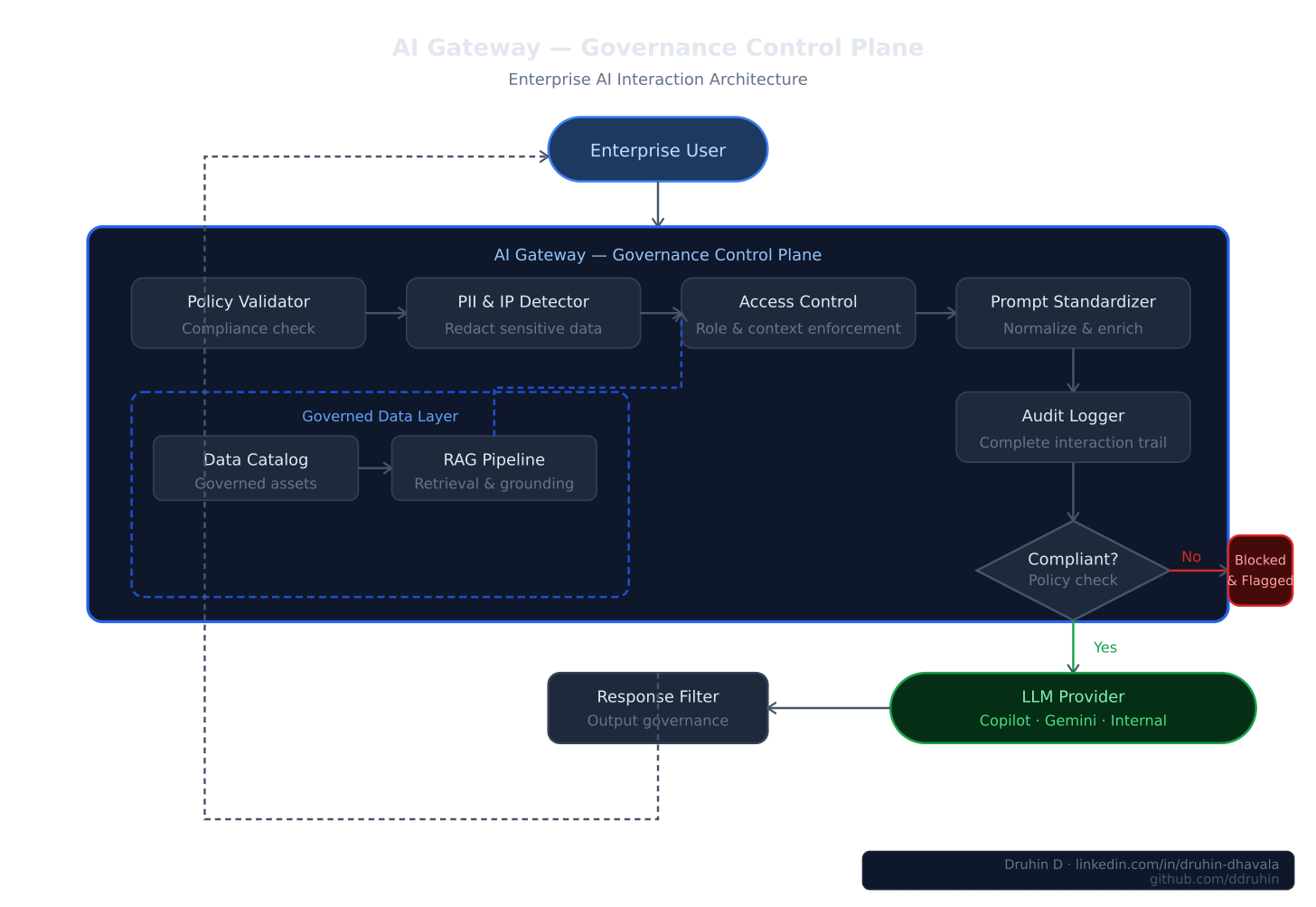
Right now, most enterprises allow direct, unmediated access to AI tools — Copilot, Gemini, internal LLM assistants. Every employee prompt travels from user to model with no interception, no validation, no policy enforcement, and no audit trail. Every interaction becomes a potential PII leak, IP exposure, policy violation, or untracked compliance event.
The teams building ahead of this problem are doing something fundamentally different.
Instead of prompts traveling directly to LLM providers, every AI interaction first passes through a governed API layer — an AI Gateway that functions as the organization’s policy enforcement point for intelligence transactions.
Before any request reaches the model, this layer:
→ Detects and redacts PII, sensitive data, and proprietary IP in real time
→ Validates prompt compliance against enterprise policy frameworks
→ Enforces access controls and data usage boundaries by role and context
→ Standardizes retrieval patterns across RAG pipelines
→ Creates a complete, auditable log of every AI interaction
→ Applies safety controls before output reaches the end user
The architectural evolution this represents is precise:
API Gateway → AI Gateway
Or stated more accurately: Governance as the control plane for AI.
This is not a proof of concept. It is a pattern being architected right now by organizations that understand the window to build this correctly closes the moment adoption scales beyond early adopters. The companies implementing this today will have audit trails, enforcement frameworks, and compliance infrastructure that their competitors will spend years attempting to retrofit.
## What Day 1 Governance Actually Requires
The organizations that will scale AI safely are not necessarily moving faster than their competitors. They are moving with intentional structure that makes speed sustainable and defensible over time.
What this requires in practice:
→ API-first design applied to every AI touchpoint across the organization — not as an afterthought but as the foundational architectural decision
→ Prompt governance and versioning treated as first-class engineering disciplines with ownership, lifecycle management, and deprecation policies
→ A clean, governed data catalog completed before RAG implementation begins — not initiated alongside it
→ LLM lifecycle policies modeled on mature API strategy frameworks, including versioning, deprecation, and ownership models
→ AI-specific observability standards that enable auditing, tracing, and explainability of every model output
→ Cross-functional governance structures that bring legal, compliance, security, and engineering into alignment before production deployment
None of this is theoretical overhead. Each element addresses a specific failure mode that organizations without governance will encounter at scale — the same failure modes that API programs spent a decade learning the hard way.
## The Trajectory Is Unmistakable
Whether the exact implementation patterns evolve or consolidate, the direction is clear: AI Governance by Design will prove decisively superior to AI Governance after Deployment — in compliance outcomes, in operational efficiency, in internal trust, and in the ability to scale without accumulating the kind of debt that becomes existential rather than merely painful.
The future enterprise AI stack will not simply be models, prompts, and vector stores. It will be policy-driven, governed, API-mediated intelligence infrastructure — where governance is not documentation sitting in a wiki or a compliance checklist completed at deployment.
It is the architecture itself.
Much like the early days of enterprise API platforms, the teams defining these governance patterns now are quietly setting the standards that the rest of the industry will spend years attempting to follow. The difference is that in AI, the cost of arriving late to governance is not measured in months of cleanup work.
It is measured in compliance exposure, eroded trust, and the compounding difficulty of retrofitting structure into systems that were never designed to accommodate it.
The window is open. It will not stay open indefinitely.
——
I have spent the last decade building and scaling enterprise API platforms across organizations managing billions in annual transaction volume. The lessons from that work — on governance architecture, lifecycle management, and the true cost of deferred structural decisions — are precisely what I am now focused on applying to enterprise AI strategy.
If this perspective resonates, I welcome the connection and the conversation.
#AIGovernance #AIGateway #EnterpriseAI #LLM #RAG #APIStrategy #GovernanceControlPlane #PlatformEngineering #ResponsibleAI #MLOps #Architecture #DigitalTransformation
About me
I’m Druhin Dhavala. I’ve built three greenfield platforms and led modernization journeys from legacy monoliths to governed API ecosystems. I carry the scars of what happens when organizations adopt new technology without guardrails — and I’m seeing the same patterns repeat as the world rushes into AI.
I’m writing here so those mistakes don’t get repeated at global scale.
If you’re building AI systems, platforms, or governance foundations, my goal is simple: help you avoid the catastrophes I’ve already lived through — before they become your reality.
This Substack is my attempt to share what’s coming, early, so you can build with clarity instead of chaos.
Connect with me on LI - https://www.linkedin.com/in/druhin-dhavala/
Git - ddruhin
Substack - Druhin Dhavala